An early overview of ICLR2017
20 Dec 2016Machine learning is accelerating, we have an idea and it is on arxiv the next day, NIPS2016 was bigger than ever and it is difficult to keep track of all the new interesting work.
Given that this is the first time I submit to ICLR, and taking advantage from all the data available of OpenReview, I have decided to make some data visualizations. I hope these visualizations help to build a mental idea of which papers are the best rated, the ones with better reviews, who is submitting them, which is the score distribution, etc.
So, let’s first see what is people saying in their abstracts in order to warm up. The next plot is a t-sne visualization of the GloVe embedding of the words found in the paper abstracts:
As expected, network, architecture, data, learning, … are in the most frequent words. On the other hand, reward, attention and adversarial do also appear as important, following the current trends of deep reinforcement learning, models with memory/attention and GANS. Note that although I performed a rough pre-processing, removing words like it, and, but, etc. there are still some common words that should be prunned.
What about which are the most prolific organizations? In order to make a histogram of the submissions per organization, we can use the affiliations field in each submission:
As it can be seen, google leads the top-50 most prolific organizations, followed by the university of Montreal, Berkeley, and Microsoft. I merged some domains like fb.com and facebook.com but there might still be some duplicities. Interestingly, the top is populated by a lot of companies, and in especial, new ones like openai surpass other well established organizations.
Quantity does not always mean quality, so for all the organizations we plot their paper count (bubble size) by mean review score.
As it can be seen google has 9 submissions with an average score of 7.5, and the biggest cluster is of 13 submissions with an average score of 6. Note that the google domain may contain deep mind, google brain and google research submissions. In case of doubt, I would like to clarify that I am not vinculated to google.
Given the acceptance rate of ICLR2016, which was close to 30%, we can make a histogram for each score value to visualize the acceptance threshold:
Finally, let’s see what interesting papers are there. For that, we can use a scatter plot where the y axis represents the number of replies the paper has (simply as a measure of “interestingness”), the average reviewer confidence in the x axis, and the average score of the paper reflected in the size and the color of the bubbles:
Given the former three parameters, we can find some interesting papers such as Bidirectional Attention Flow for Machine Comprehension, Neural Architecture Search with Reinforcement Learning, and Discrete Variational Autoencoders. Bubbles are clickable, linked to the respective openreview pages, and I added some jitter so that they are separated when zooming in. I encourage the reader to browse through the data to find the gems hidden in there.
For a more explicit visualization I also include a top-10 papers sorted first by average score and then by confidence (score is the raw average, not ponderated).
This unveils the top rated paper, which is Understanding deep learning requires rethinking generalization!
Data was extracted on 21st December, so there might be some variations in the numbers.
What happened after reviews?
The final acceptance distribution has turned out to be similar to the rating histogram plotted above in this post as it can be seen in the “ICLR 2017 Conference Statistics” twitted by @OriolVinyalsML:
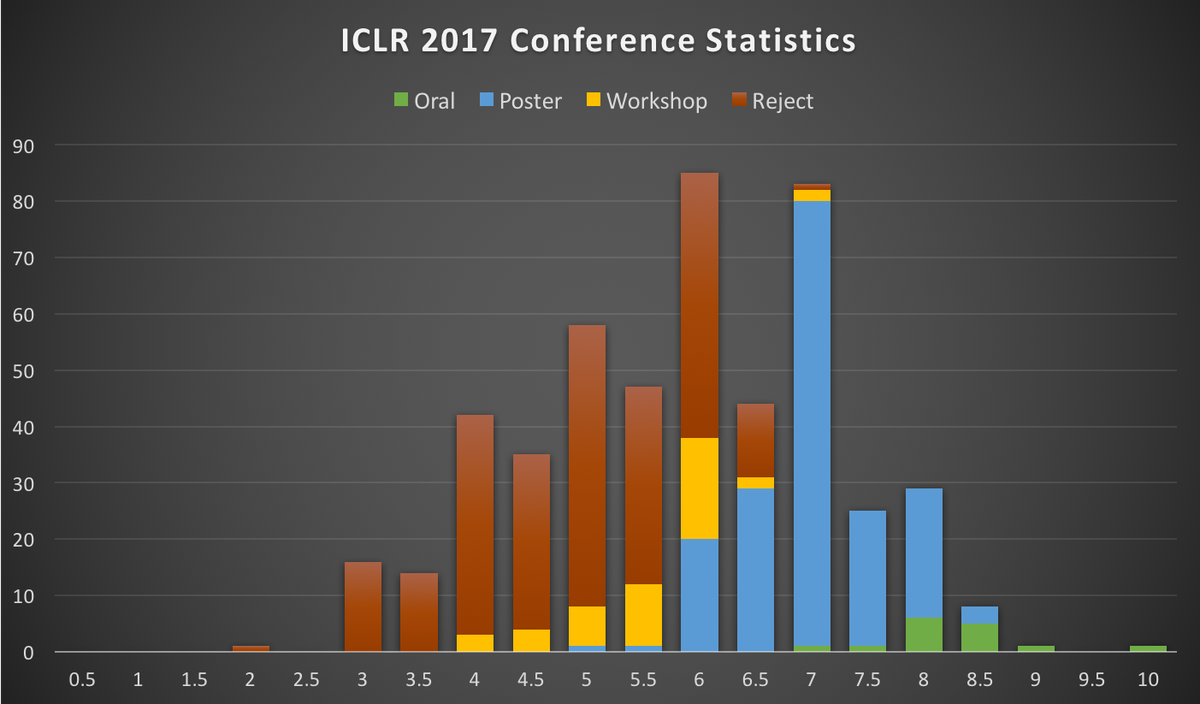
In fact, the final results show that the hard 6.5 threshold I plotted is spread between 6.5 and 6. Congratulations to those papers accepted with a 5 and a 5.5 :). It is also interesting to see that papers in the 7-10 range have achieved to be oral.
@karpathy has posted the detailed list of the oral, poster, and workshop papers on Medium, as well as a nice comparative with arxiv-sanity.
About the data
Openreview loads the data asynchronously using javascript, thus python and urllib are not an option. In these cases it is necessary to use selenium, which allows us to use the chromium engine (or any other one) to execute the scripts and to get the data. Nevertheless, I will pack the data into json format and upload it here so that anyone interested in it can skip all the previous steps (and to avoid overloading OpenReview).
Acknowledgements
I would like to thank @pepgonfaus for helping to obtain the data and sharing new ideas.
Thanks the Reddit ML community for helping me to improve this page.
Related posts
Carlos E. Perez has written a couple of interesting articles: Deep Learning: The Unreasonable Effectiveness of Randomness, where he predicted some of the best rated papers discovered in this blog post, and Ten Deserving Deep Learning Papers that were Rejected at ICLR 2017, where he comments on those interesting articles that were rejected.