GSOC2017: RNNs on tiny-dnn
27 Aug 2017 Recurrent Neural Networks (RNNs) are now central to many applications, from speech recognition to
Computer Vision. Some examples are Image captioning, Visual Question
Answering (VQA), autonomous
driving,
and even Lip reading.
Recurrent Neural Networks (RNNs) are now central to many applications, from speech recognition to
Computer Vision. Some examples are Image captioning, Visual Question
Answering (VQA), autonomous
driving,
and even Lip reading.
During this Google Summer of Code, I have extended the tiny-dnn framework with an RNN API, thus making it able to train on sequential data, where data points depend on each other in the time domain. Performing these extensions in tiny-dnn is especially challenging (and fun) because:
- The library is growing fast, thus making the pull requests obsolete really fast.
- The library was initially thought for simple feedforward convolutional neural
networks, thus only caring about input, output, weights, and biases.
- However, RNNs do have also hidden states which must not be fed to the next layers but to the next timesteps. Thankfully, tiny-dnn contemplates a third type: aux vectors, which perfectly fit for hidden states.
- Another related smaller issue
has been the fact that RNNs usually use multiple weight matrices. The only
implication of this has been the modification of the
fan_inandfan_outfunctions in layer to accept indices for each weight matrix (important for initialization).
- Handling sequential data inputs.
- Decoupling the state handling from the cell type. Namely, being able to change the recurrent cell (RNN, LSTM, GRU), and reusing the code to forward or reset the multiple timesteps.
- Gradient checks were initially thought to work on the whole network, comparing with the loss function, and using a single weight matrix. I had to create a new black box gradient check, and modify the initial one to handle multiple weight matrices.
The milestones of this project have been:
- Creating a functional rnn cell.
- Creating a wrapper for batching sequential data.
- Extending it to LSTMs and GRU
- Providing working examples and documentation.
Which are summarized in the following main PRs:
- #768: Single step recurrent cell.
- #806: Full RNN API with state transitions, LSTM, GRU, examples, and docs.
And the following minor PRs:
- #818: Blackbox gradient check.
- #848: Gradient check with multiple weight matrices.
- #856: Guess batch_size from gradient vectors (because non-recurrent layers have batch_size = sequence length * batch_size.
- #776: Transition to
size_t.
Results
A new simple RNN API for tiny-dnn. Creating a recurrent neural network is as easy as:
network<sequential> nn;
nn << recurrent_layer(gru(input_size, hidden_size), seq_len);
Where recurrent_layer acts as a wrapper for the recurrent cells, i.e. gru,
rnn, or lstm, defined in cells.h. This wrapper receives data with
dimensionality (seq_len * batch_size, data_dim1, data_dim2, etc.), being the
sequential dimension the leftmost in row-major order, and iterates
seq_len times. These are the most important methods:
seq_len(int): sets the sequence length.bptt_max(int): sets the max number of steps to remember with Truncated Back-Propagation Trough Time (more info here).clear_state(): clears current state vectors.
In test time we do not need to save all the state transitions, thus, we can set
the sequence length to one and the bptt_max to the desired number of steps to
remember.
Examples
Two examples have been provided:
- Two-number addition:
A model that learns to add two given numbers.
Input numbers between -1 and 1. Input number 1: 0.1 Input number 2: 0.4 Sum: 0.514308 Input number 1: 0.6 Input number 2: -0.9 Sum: -0.299533 Input number 1: 1.0 Input number 2: 1.0 Sum: 1.91505 # performance is worse at the extremes Input number 1: 0 Input number 2: 0 Sum: 0.00183523 - Char-rnn gitter
bot. Trains a
recurrent model on a gitter room history. This example is based on Karpathy’s
char-rnn example, i.e. training the model
to predict the next character from the previous ones. It includes:
- Training Code.
- Testing Code.
- Python wrapper.
- Gitter API helper functions with PyCurl.
- Three-layer GRU with 256 hidden units trained on tiny-dnn/developers with Adam:
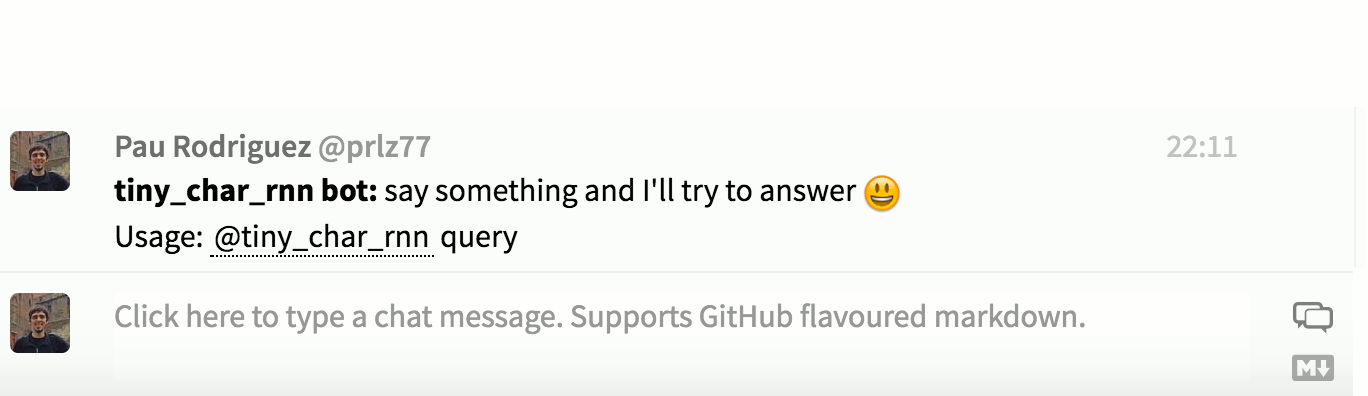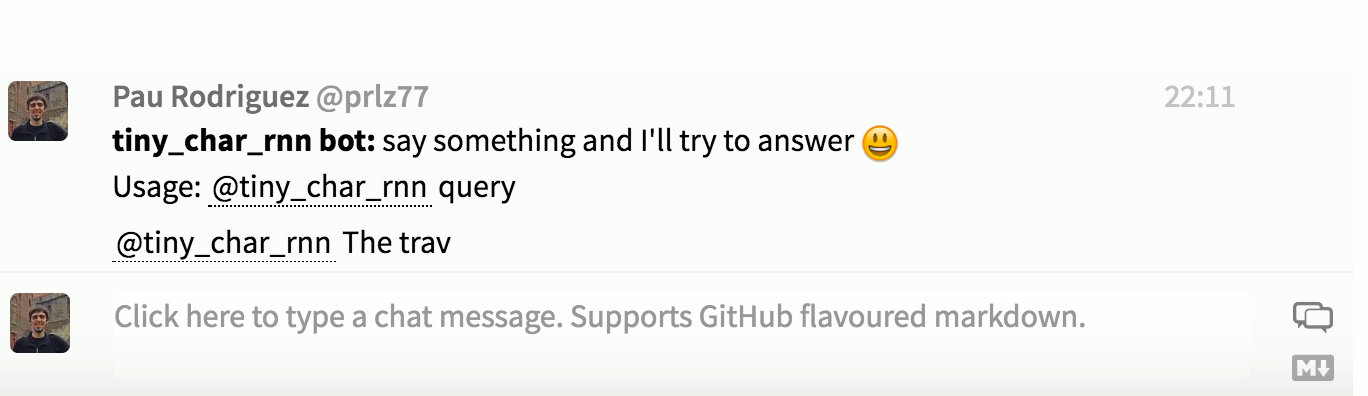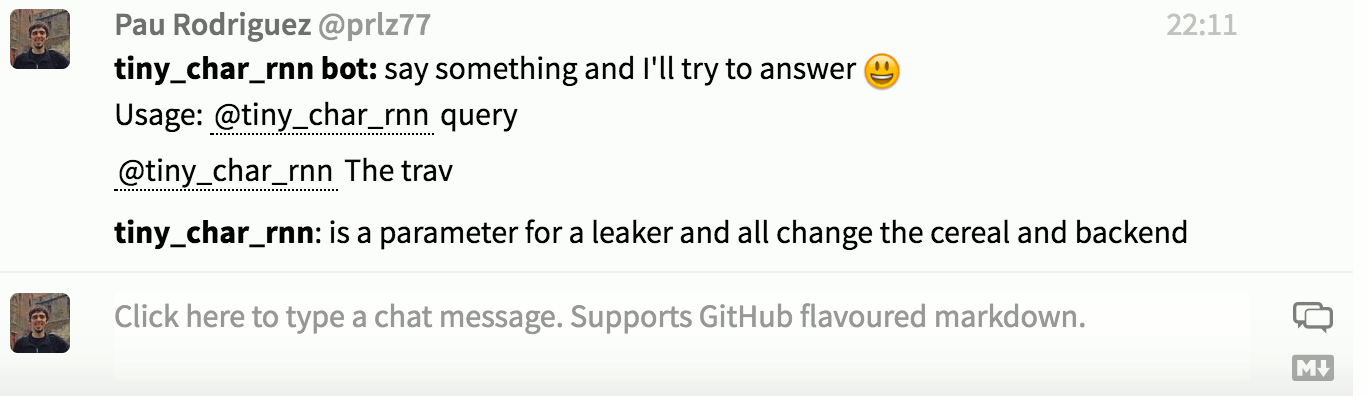
It also autocompletes usernames and references other users:
> @tiny_char_rnn karandesai-9
tiny_char_rnn: 6 @bhack @beru @bhack @/all how about the network definitely in
decided on data
We can use temperature to make predictions more certain. These are some outputs of the rnn at different temperatures (without any user input):
> t=1.0
<<-<--z><->
decai-9 change bhack @karandesai-96 @beru @beru @bhack @/acb96 @beru @beru @beru
@beru @beru @b
han @edgarriba @bhack @beru @beru @beru @beru @beru @beru @beru @beru
> t=0.75
a code after a fector back end a becement a class back in finc eed flack code
and a back clang a cal base different caffe check flacting a change class
all hape a change different caffe check file file find a change is face a because a call get
> t=0.5
a did ead a decided in a ging a fector class but i am decided in a ging clang
and backend on can be and factivation for each in the code and a commend
of of the layer for element in see a factivation for decide.
> t=0.1
checked the new can be contribute it is the tests and it is the and backend that
in the order from teached the tensorflow the pr the tests and it is the and
pretty i can to try to make a lot of tests are the first tensor that we can
travis to complete check this one the tests and it is the and fine of the code
it is the tests and it is to see a lot of tests to make a pr integrated in the
code for extensor integration
Acknowledgements
This work has been done under the supervision of @edgarriba, @nyanp, and @bhack.
Final thoughts
Apart from giving me the opportunity to contribute to an exciting open-source project like tiny-dnn, this Google Summer of Code has allowed me to deepen my knowledge and understanding on the topics of my Ph.D. If you are eligible, I totally recommend you to apply.